- Введение
- Apache KAFKA
- Структура данных Apache Kafka
- Развертывание кластера KAFKA
- Тестируем отказоустойчивость кластера Apache Kafka:
- РАЗБОР СТРУКТУРЫ ДАННЫХ APACHE KAFKA НА ПРАКТИКЕ
- ВЫВОДЫ
- ПОЛЕЗНЫЕ ССЫЛКИ
Введение
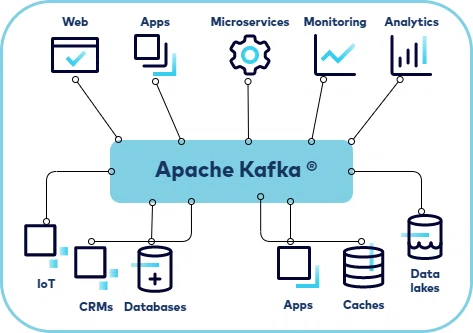
Брокеры сообщений - это звенья между отправителем и получателем сообщений в системах распределенных приложений. Они предоставляют методы передачи сообщений между приложениями и компонентами, что является одним из ключевых механизмов для асинхронного обмена данными в современных информационных системах. В данной статье рассмотрим платформу Apache Kafka - распределенная система обмена сообщениями, которая позволяет передавать потоки данных между различными приложениями и сервисами.
Распределенная система
Распределенная система — это набор компьютерных программ, использующих вычислительные ресурсы нескольких отдельных вычислительных узлов для достижения одной общей цели. Ее также называют распределенными вычислениями или распределенной базой данных. Распределенная система основывается на отдельных узлах, которые обмениваются данными и выполняют синхронизацию в общей сети. Обычно узлы представляют собой отдельные физические аппаратные устройства, но это могут быть и отдельные программные процессы или другие рекурсивные инкапсулированные системы. Распределенные системы направлены на устранение узких мест или единых точек отказа в системе.
Распределенные вычислительные системы обладают следующими характеристиками.
- Совместное использование ресурсов: в распределенной системе могут совместно использоваться оборудование, программное обеспечение или данные.
- Параллельная обработка: одну и ту же функцию могут одновременно обрабатывать несколько машин.
- Масштабируемость: вычислительная мощность и производительность могут масштабироваться по мере необходимости при добавлении дополнительных машин.
- Обнаружение ошибок: упрощается обнаружение отказов.
- Прозрачность: узел может обращаться к другим узлам в системе и обмениваться с ними данными.
В централизованной вычислительной системе все вычисления выполняются на одном компьютере и в одном месте. Основное различие между централизованными и распределенными системами заключается в модели взаимодействия между узлами системы. Состояние централизованной системы хранится в центральном узле, к которому индивидуально обращаются клиенты. Поскольку все узлы централизованной системы обращаются к центральному узлу, это может привести к перегрузке сети и замедлить ее работу. Централизованная система имеет единую точку отказа, тогда как в распределенной системе такой точки нет.
Межсервисное взаимодействие
Выделяют 2 основных типа взаимодействия между сервисами: синхронное и асинхронное.
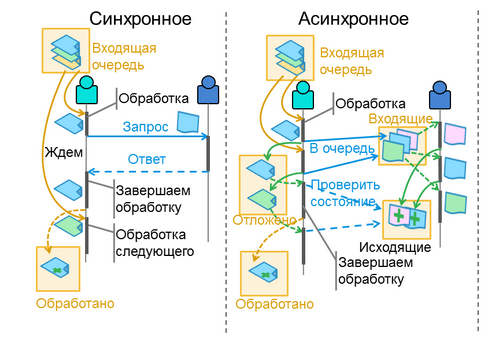
Синхронное взаимодействие сервисов означает, что один сервис должен дожидаться ответа от другого сервиса, прежде чем продолжать свою работу. Например, если сервис A должен получить данные из сервиса B, он должен отправить запрос на данные и дождаться ответа от сервиса B, прежде чем продолжить свою работу.
Асинхронное взаимодействие сервисов означает, что сервисы взаимодействуют между собой без ожидания ответа друг друга. Вместо этого, каждый сервис отправляет запрос на выполнение задачи, а затем продолжает работу, не ожидая ответа.
Более детально ознакомиться с способами межсетевого взаимодействия можно по этой статье на Habr
Классические сервисы очередей
Системы очередей обычно состоят из трёх базовых компонентов:
- сервер(брокер),
- продюсеры, которые отправляют сообщения в некую именованную очередь, заранее сконфигурированную администратором на сервере,
- консьюмеры, которые считывают те же самые сообщения по мере их появления.
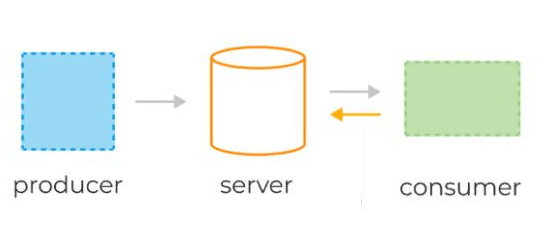
В веб-приложениях очереди часто используются для отложенной обработки событий или в качестве временного буфера между другими сервисами, тем самым защищая их от всплесков нагрузки.
Консьюмеры получают данные с сервера(брокера), используя две разные модели запросов: pull или push.
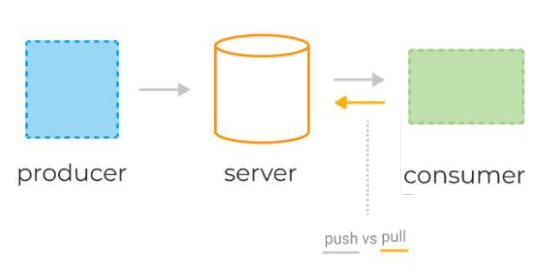
pull-модель — консьюмеры сами отправляют запрос раз в n секунд на сервер для получения новой порции сообщений. При таком подходе клиенты могут эффективно контролировать собственную нагрузку. Кроме того, pull-модель позволяет группировать сообщения в батчи, таким образом достигая лучшей пропускной способности. К минусам модели можно отнести потенциальную разбалансированность нагрузки между разными консьюмерами, а также более высокую задержку обработки данных.
push-модель(RabbitMQ) — сервер делает запрос к клиенту, посылая ему новую порцию данных. Она снижает задержку обработки сообщений и позволяет эффективно балансировать распределение сообщений по консьюмерам.
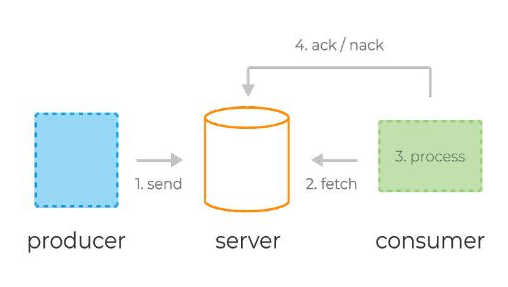
Типичный жизненный цикл сообщений в системах очередей:
- Продюсер отправляет сообщение на сервер.
- Консьюмер фетчит (от англ. fetch — принести) сообщение и его уникальный идентификатор сервера.
- Сервер помечает сообщение как in-flight. Сообщения в таком состоянии всё ещё хранятся на сервере, но временно не доставляются другим консьюмерам. Таймаут этого состояния контролируется специальной настройкой.
- Консьюмер обрабатывает сообщение, следуя бизнес-логике. Затем отправляет ack или nack-запрос обратно на сервер, используя уникальный идентификатор, полученный ранее — тем самым либо подтверждая успешную обработку сообщения, либо сигнализируя об ошибке.
- В случае успеха сообщение удаляется с сервера навсегда. В случае ошибки или таймаута состояния in-flight сообщение доставляется консьюмеру для повторной обработки.
Apache KAFKA
Данная платформа применяется для создания конвейеров потоковой передачи данных в реальном времени и приложений, которые адаптируются к потокам данных. В ней объединены обмен сообщениями, хранение и потоковая обработка информации. Благодаря этому можно хранить и анализировать как старые данные, так и те, что поступают в реальном времени.
Kafka дает пользователям три основные функции:
- Публиковать и подписываться на потоки записей
- Эффективно хранить потоки записей в порядке их создания
- Обрабатывать потоки записей в режиме реального времени
Основными сущностями для Apache Kafka являются:
- Broker - это основной компонент, который отвечает за хранение и управление потоками данных. Он получает, сохраняет и распределяет сообщения между производителями и потребителями.
- ZooKeeper - отдельный вспомогательный продукт для хранения состояния кластера, конфигурации и метаданных.
- Кластер Kafka - группа брокеров Kafka, которые работают вместе для хранения и обработки сообщений. Кластер обеспечивает масштабируемость, отказоустойчивость и распределение нагрузки.
- Producer - это компонент, который создает и отправляет сообщения в брокер Kafka. Продюсер может быть связан со множеством тем (topics) и может отправлять сообщения в несколько брокеров.
- Topic - категория или канал, в который производитель (producer) публикует сообщения, а потребитель (consumer) считывает их. Топик представляет собой логическую единицу группировки сообщений. Отправляются они в том же порядке что и поступили (FIFO).
- Consumer — это компонент, который считывает и обрабатывает сообщения из брокера Kafka. Потребитель может быть связан со множеством тем и получать сообщения из нескольких брокеров. Потребители читают сообщения из разделов (partitions) в пределах темы и сохраняют свое смещение (offset) для отслеживания прогресса чтения.
Как и сервисы обработки очередей, Kafka условно состоит из трёх компонентов:
- сервер (брокер),
- продюсеры — они отправляют сообщения брокеру,
- консьюмеры — считывают эти сообщения, используя модель pull.
Пожалуй, фундаментальное отличие Kafka от очередей состоит в том, как сообщения хранятся на брокере и как потребляются консьюмерами.
- Сообщения в Kafka не удаляются брокерами по мере их обработки консьюмерами — данные в Kafka могут храниться днями, неделями, годами.
- Благодаря этому одно и то же сообщение может быть обработано сколько угодно раз разными консьюмерами и в разных контекстах.
В этом кроется главная мощь и главное отличие Kafka от традиционных систем обмена сообщениями.
В Кафке применяется подход на основе pull модели, позволяющий пользователям запрашивать пакеты сообщений с определенных оффсетов. Пользователи могут использовать пакетную обработку сообщений для повышения пропускной способности и эффективной доставки сообщений.
Для чего используется Apache Kafka?
Apache Kafka лучше всего подходит для потоковой передачи от А к Б без сложной маршрутизации, но с максимальной пропускной способностью. Инструмент отлично справляется с потоковой обработкой и моделированием изменений в системе в качестве последовательности событий. Кафку также можно использовать для обработки данных при многоэтапной конвейерной обработке. Кафка станет отличным решением, если нужен фреймворк для хранения, чтения, повторного чтения и анализа потоковых данных. Ее сильная сторона – обработка и анализ данных в реальном времени. Инструмент идеально подходит для постоянного хранения сообщений или для регулярно проверяемых систем.
Где может быть использована Apache Kafka?
- Логи и метрики: Kafka может использоваться для сбора, хранения и анализа логов и метрик для извлечения ценной информации о системе.
- Микросервисная архитектура: Apache Kafka может быть использован для связи и синхронизации между микросервисами в распределенной системе. Он может использоваться для передачи сообщений и событий между различными сервисами, обеспечивая надежную доставку и гарантию обработки сообщений.
- Обработка потоков данных: Apache Kafka может использоваться для обработки потоков данных в реальном времени. Он может принимать потоки данных с различных источников, например, датчиков, IoT-устройств и т. д., и обрабатывать их практически мгновенно. Это делает его идеальным для решения задач машинного обучения, анализа данных и мониторинга.
- Анализ веб-потребителей: Apache Kafka может быть использован для анализа веб-потребителей, обрабатывая данные в реальном времени из различных источников. Например, это может быть использовано для построения системы рекомендаций, которая обрабатывает данные о поведении пользователей и предоставляет персонализированные рекомендации.
- Интеграция и потоковая обработка данных: Apache Kafka может использоваться для интеграции и обработки данных в реальном времени с другими системами, такими как базы данных, системы управления данными и другие источники данных. Он предоставляет мощные средства для выполнения потоковых преобразований данных и агрегации.
- Журналы персистентности: Kafka может использоваться в качестве журналов персистентности для сохранения и восстановления данных. Он может быть использован для записи и восстановления состояния системы в случае сбоев. И др.
Структура данных Apache Kafka
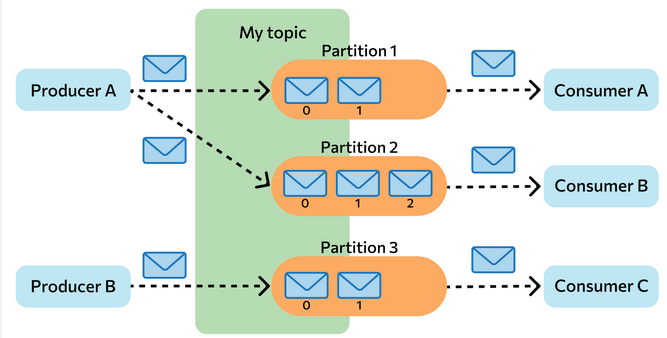
Сообщения в Kafka организованы и хранятся в именованных топиках (Topics), каждый топик состоит из одной и более партиций (Partition), распределённых между брокерами внутри одного кластера. Подобная распределённость важна для горизонтального масштабирования кластера, так как она позволяет клиентам писать и читать сообщения с нескольких брокеров одновременно.
Когда новое сообщение добавляется в топик, на самом деле оно записывается в одну из партиций этого топика. Сообщения с одинаковыми ключами всегда записываются в одну и ту же партицию, тем самым гарантируя очередность или порядок записи и чтения.
Для гарантии сохранности данных каждая партиция в Kafka может быть реплицирована n раз, где n — replication factor. Таким образом гарантируется наличие нескольких копий сообщения, хранящихся на разных брокерах.
У каждой партиции есть «лидер» (Leader) — брокер, который работает с клиентами. Именно лидер работает с продюсерами и в общем случае отдаёт сообщения консьюмерам. К лидеру осуществляют запросы фолловеры (Follower) — брокеры, которые хранят реплику всех данных партиций. Сообщения всегда отправляются лидеру и, в общем случае, читаются с лидера.
Чтобы понять, кто является лидером партиции, перед записью и чтением клиенты делают запрос метаданных от брокера. Причём они могут подключаться к любому брокеру в кластере. 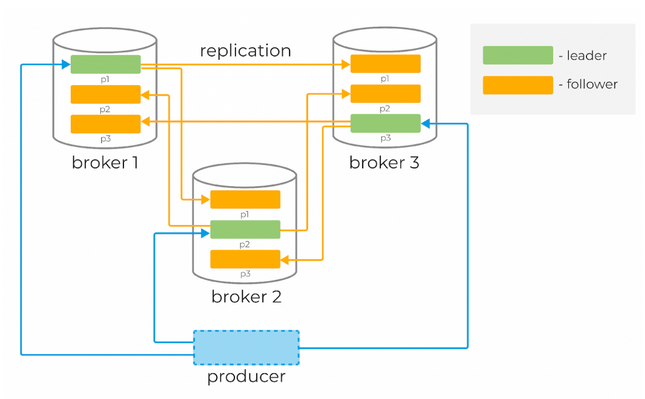
Основная структура данных в Kafka — это распределённый, реплицируемый лог. Каждая партиция — это и есть тот самый реплицируемый лог, который хранится на диске. Каждое новое сообщение, отправленное продюсером в партицию, сохраняется в «голову» этого лога и получает свой уникальный, монотонно возрастающий offset (64-битное число, которое назначается самим брокером).
Данные топика Kafka обычно состоят из трех типов файлов: .log файлы, .index файлы и .timeindex файлы. Каждый из этих файлов содержит разные данные и информацию о смещениях (offsets) сообщений в топике:
- .log: содержат фактические сообщения, отправленные в топик. Каждое сообщение записывается в отдельную строку файла .log. Файлы .log содержат сырые данные и используются для хранения сообщений Kafka на диске.
- .index: содержат индексы для быстрого поиска сообщений в файлах .log. Каждый индекс указывает на смещение (offset) сообщения в файле .log. Индексы облегчают процесс поиска сообщений по смещению, что делает его более эффективным и быстрым.
- .timeindex: содержат индексы, основанные на времени, для быстрого поиска сообщений в файлах .log. Каждый индекс указывает на смещение (offset) сообщения в файле .log, связанное с определенным временем. Это позволяет быстро найти все сообщения, отправленные в определенный временной диапазон.
Вместе эти файлы позволяют Kafka эффективно хранить и обрабатывать сообщения в топиках. Отслеживая смещения (offsets), можно легко переносить последовательные сообщения и найти конкретное сообщение по времени или смещению.
Так мы уже выяснили, сообщения не удаляются из лога после передачи консьюмерам и могут быть вычитаны сколько угодно раз.Время гарантированного хранения данных на брокере можно контролировать с помощью специальных настроек. Длительность хранения сообщений при этом не влияет на общую производительность системы. Поэтому совершенно нормально хранить сообщения в Kafka днями, неделями, месяцами или даже годами.
Развертывание кластера KAFKA
- Установка пакета и создание системы директорий
- Создаем папку для кластера
- Создадим рабочие директории для трех узлов kafka_server_1, kafka_server_2 и kafka_server_3.
- Скачиваем, распаковываем и копируем содержимое в каждую из директорий брокеров https://kafka.apache.org/downloads:
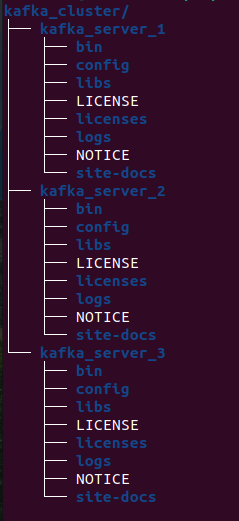
- Настройка узлов
- Конфигурация Kafka-брокера(из директорий kafka_server_1, kafka_server_2 и kafka_server_3 соответственно)
config/server.properties- id брокера(0, 1, 2)
- клиентский порт( 9092, 9093, 9094)
- порт Zookeeper(2181, 2182, 2183)
- директории логов(/tmp/kafka-logs-1, /tmp/kafka-logs-2, /tmp/kafka-logs-3)
broker.id=0
listeners=PLAINTEXT://:9092
zookeeper.connect=localhost:2181
log.dirs=/tmp/kafka-logs-1- Конфигурация Zookeeper node:
config/server.properties- директория для данных (/tmp/zookeeper_1, /tmp/zookeeper_2, /tmp/zookeeper_3)
- клиентский порт(2181, 2182, 2183)
- максимальное количество клиентских соединений и лимиты соединения
- порты обмена данными между узлами(т.е. сообщаем каждому узлу о существовании других)
dataDir=/tmp/zookeeper_1
clientPort=2181
maxClientCnxns=60
initLimit=10
syncLimit=5
tickTime=2000
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890 - Создание директорий для узлов Zookeeper, запись id узлов в служебные файлы:
mkdir -p /tmp/zookeeper_[1..3]
echo "1" >> /tmp/zookeeper_1/myid
echo "2" >> /tmp/zookeeper_2/myid
echo "3" >> /tmp/zookeeper_3/myid
- Запуск zookeeper-узлов и брокеров
Для запуска кластера необходимо с каждой корневой директории( kafka_server_1, kafka_server_2 и kafka_server_3) запустить скрипты:
sudo bin/zookeeper-server-start.sh config/zookeeper.pro- Создание топика, продюсера и консьюмера:
sudo bin/kafka-topics.sh --create --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --replication-factor 3 --partitions 3 --topic TestTopic
Создали тему(topic) с 3-мя партициями на 3-х серверах и продублировали все партиции на каждом сервере(replication factor).
Узнать информацию по топику можно следующей командой:
bin/kafka-topics.sh --describe --topic TestTopic --bootstrap-server localhost:9094
Получаем:

- Leader — сервер с основным экземпляром партиции
- replica — сервер, на котором информация дублируется
- ISR — сервера, берущие на себя роль лидеров в случае отказа leader
Тестируем отказоустойчивость кластера Apache Kafka:
- Для начала создаем консольные продюсера и консьюмера:
sudo bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic TestTopic
sudo bin/kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --from-beginning --topic TestTopic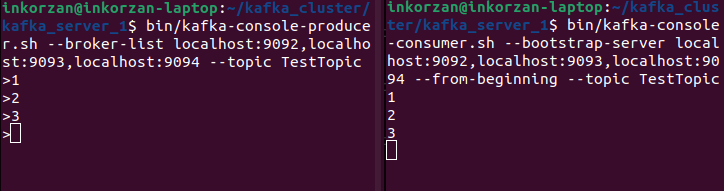
Справа поднят продюсер, который отправляет сообщение, слева - консъюмер, который считывает.
- Остановим один из узлов kafka(kafka_server_1):

Видим, что параметры Leader и Isr изменился. Для Partition: 1 изменился лидер c первого брокера с id=0 на второй c id=1, как и должно быть по параметру Isr.
Попробуем написать сообщение после остановки первого брокера:
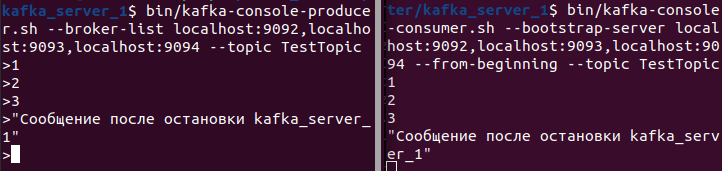
Видим, что сообщение дошло.
- Остановим один из узлов kafka(kafka_server_1):

Так как остался работать только один брокер, соответственно он становиться лидером для всех партиций.
Попробуем написать новое сообщение:
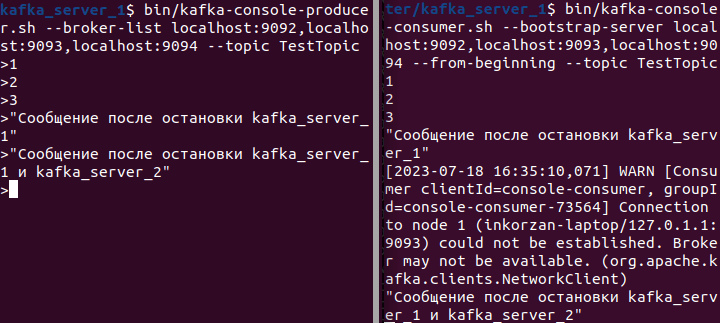
Видим, что и в этот раз, сообщение дошло. Таким образом наблюдаем отказоустойчивость кластера Kafka.
РАЗБОР СТРУКТУРЫ ДАННЫХ APACHE KAFKA НА ПРАКТИКЕ
- Создадим новый топик с 3-мя портициями и 3-мя репликами на 3-х брокерах, чтобы сделать запись равномерной по всем партициям с одного консьюмера необходимо добавить класс RoundRobin в config/producer.properties
partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner )
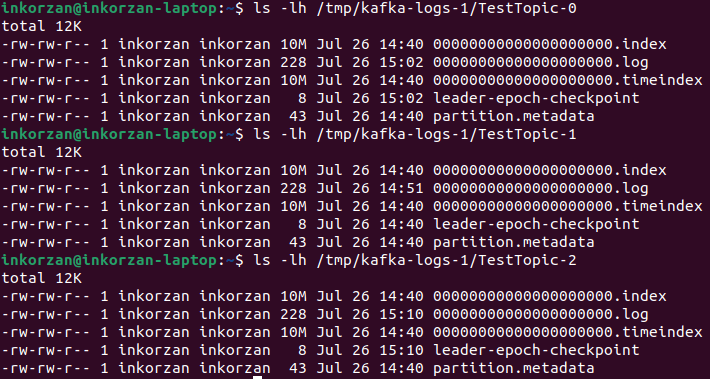
В каталогах журналов kafka-брокеров созданы 3 каталога:
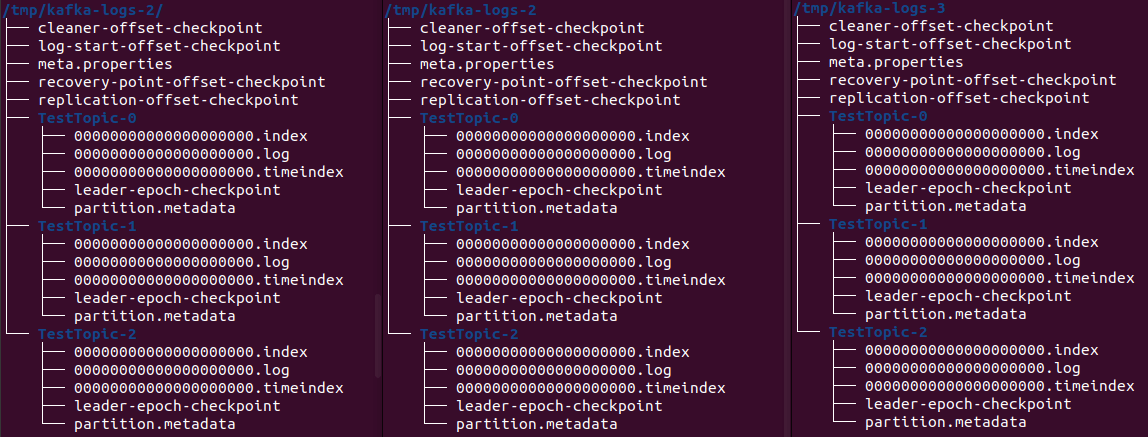
Мы создали в топике три партиции, и у каждой — свой каталог в файловой системе на каждом брокере. В leader-epoch-checkpoint хранится информация о текущем эпохальном номере лидера и его идентификаторе, а также информация о последнем примененном и отправленном записях журнала для каждого лидера. Это используется для контроля над повторными операциями и переупорядочивании записей при аварийной ситуации или смене лидера. В partition.metadata содержат информацию о каждом разделе топика в кластере Kafka. Они включают следующую информацию:
- Идентификатор раздела (Partition ID): уникальный идентификатор раздела внутри топика.
- Идентификатор топика (Topic ID): идентификатор топика, к которому принадлежит раздел.
- Лидер раздела (Leader): брокер, который является лидером раздела и отвечает за чтение и запись данных в этот раздел.
- Реплики раздела (Replicas): все брокеры, которые содержат копию данного раздела.
- Версия (Version): текущая версия метаданных раздела.
- Состояние (State): состояние раздела, такое как "Online" или "Offline".
Так же виден параметр log-start-offset-checkpoint, который используется в Apache Kafka для сохранения информации о последнем записанном оффсете (смещении) в логе каждой партиции, что необходимо для продолжения считывания данных с места, на котором остановился консьюмер. Также используется для восстановления после сбоя. Если брокер Kafka аварийно выходит из строя, он восстанавливается из последнего сохраненного checkpoint-файла. Это позволяет восстановить данные и состояние брокера до момента сбоя.
- Добавим в топик несколько сообщений. Подключимся к первому брокеру продюсером, который является лидером одной из партиций и отправим в него несколько сообщений:

Сообщения записываются в файл .log, соответственно можем увидеть куда записались сообщения - в портицию TestTopic-1:
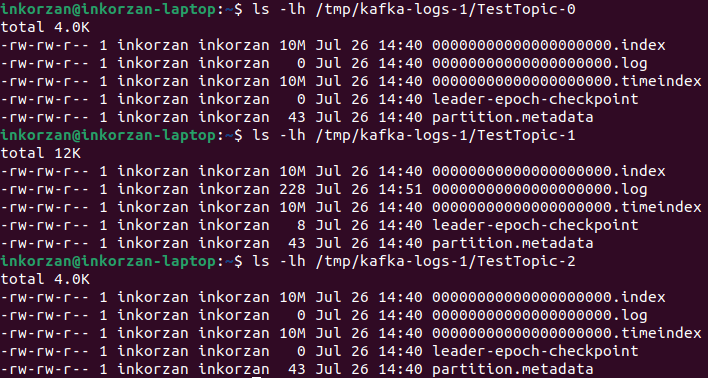
Каждому новому сообщению в партиции присваивается Id на 1 больше предыдущего. Этот Id еще называют смещением (offset). У первого сообщения смещение 0, у второго — 1 и т. д., каждое следующее всегда на 1 больше предыдущего. Проверим на нашем примере инструментом kafka:
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/kafka-logs-1/TestTopic-1/00000000000000000000.log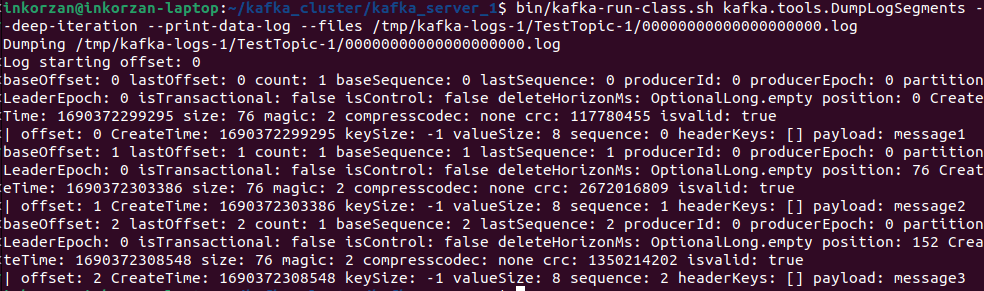
Здесь мы видим смещение(offset), время создания(Create Time), размер ключа(keySize) и значения(valueSize) , а еще само сообщение (payload).
- Убедимся в том, что при подключении к разным брокерам - запись осуществляется только в одну партицию, для которой брокер является лидером. Подключимся ко второму брокеру и запишем в него несколько сообщений:

Проверим в какую партицию были записаны данные:
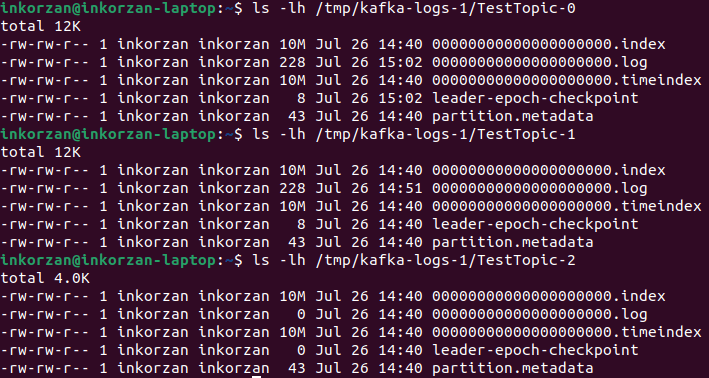
Размер лог файла TestTopic-0 изменился, проверим есть ли там сообщения, которые мы отправили на второй брокер:
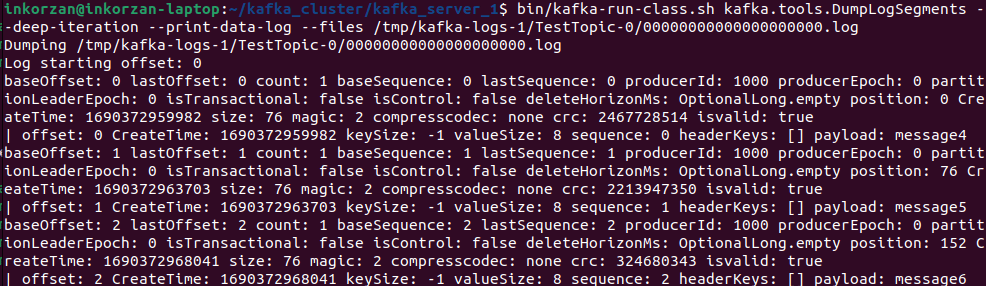
Видим, что отправленные сообщения записались в партицию TestTopic-0.
Повторим все действия для третьего брокера:

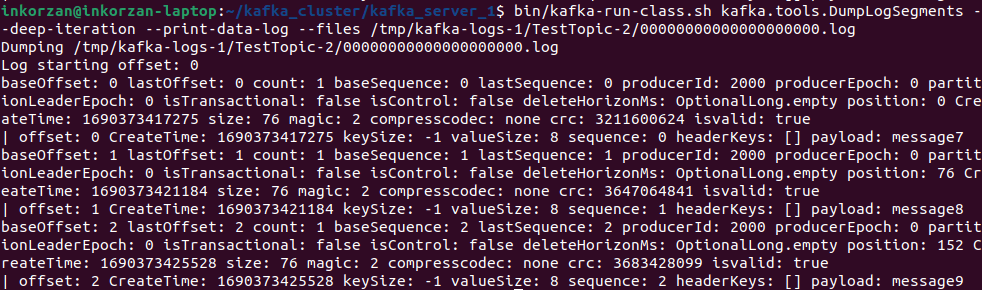
Делаем вывод, что первый брокер является лидером партиции TestTopic-1, второй брокер - TestTopic-0, а третий TestTopic2.
ВЫВОДЫ
Основные преимущества Apache Kafka состоят в его высокой масштабируемости, отказоустойчивости и скорости обработки данных. Он способен обрабатывать и обеспечивать передачу данных на миллионы сообщений в секунду, что делает его идеальным выбором для использования в высоконагруженных системах. Apache Kafka также обладает гибкой архитектурой и поддерживает многоязыковые API, что позволяет разработчикам интегрировать его с различными приложениями и платформами. Он также поддерживает масштабирование как горизонтальное, так и вертикальное, что позволяет легко развивать и изменять систему в соответствии с изменяющимися потребностями. В целом, Apache Kafka является мощной и эффективной системой для обработки потоков данных в реальном времени. Он предоставляет широкие возможности для разработчиков и позволяет им эффективно управлять и обрабатывать большие объемы данных.
ПОЛЕЗНЫЕ ССЫЛКИ
- официальный ресурс Apache Kafka
- файлы для установки Apache Kafka
- Apache Kafka: основы технологии
- понимание брокеров сообщений
- пример развертывания кластера Apache Kafka
- установка Apache Kafka Cluster
- практический взгляд на хранение данных в Apache Kafka
- взаимодействие сервисов
Также читайте:
