
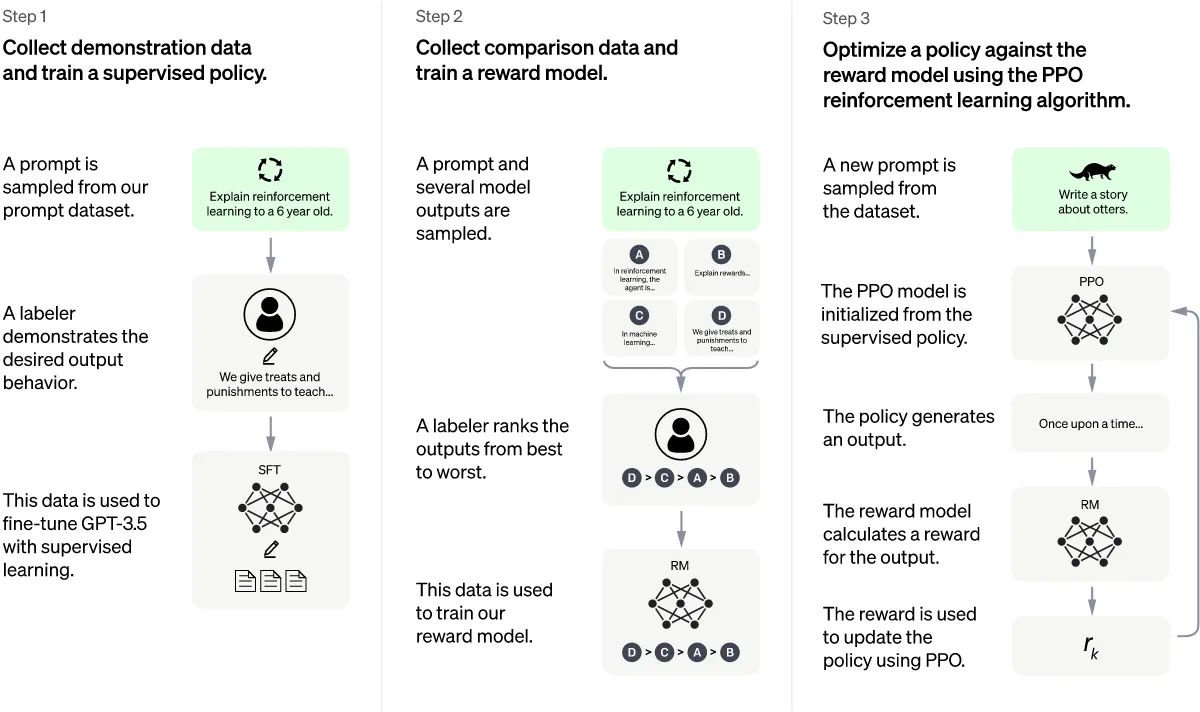
Основной принцип: Использование Reinforcement Learning from Human Feedback (RLHF). RLHF предусматривает оценку людьми ответов модели и использование этой оценки для коррекции ответов.
Краткая суть: Взяли модель GMT3, дообучили на ответах живых людей, получилась GMT 3.5. Обучили ещё одну модель Reward Model, чтоб она давала оценку ответу модели GMT 3.5 (данные для обучения опять генерировали живые люди). Улучшили модель GMT3.5 используя обучение с подкреплением, получили ChatGPT.
Подробнее:
- Supervised Fine Tuning (SFT) Model (GMT 3.5 Model)
- Сбор данных: Выбирается некоторый запрос из базы, человек даёт желаемый ответ.
- Эти данные используются для дообучения GPT 3 при помощи обучения с учителем. Таким образом получили модель SFT (или GMT 3.5)
- Reward Model (нужна для использования обучения с подкреплением)
- Сбор данных: Выбирается некоторый запрос из базы, GMT 3.5 генерирует несколько ответов, человек сортирует эти ответы от лучшего к худшему.
- Эти данные используются для обучения модели вознаграждения. Вход: пара запрос-ответ. Выход: оценка (число).
- Используем обучение с подкреплением
- Обновляется “политика” модели GMT 3.5 при помощи метода Proximal Policy Optimization (PPO):
- Выбирается запрос из базы.
- Модель генерирует ответ.
- Reward Model генерирует оценку.
- Возвращаемся к шагу 2 (фиксированное число раз, потом к шагу 1).
- В процессе выполнения должна меняться политика модели так, чтобы максимизировать оценку, которая генерируется моделью Reward Model.
ИСТОЧНИКИ
Также читайте:
