
Key Principle:Use Reinforcement Learning from Human Feedback (RLHF). RLHF involves humans evaluating the model's responses and using that evaluation to adjust the responses.
Brief summary: We took the GMT3 model, additionally trained it on the answers of living people, and the result was GMT 3.5. We trained another Reward Model so that it would evaluate the response of the GMT 3.5 model (training data was again generated by real people). We improved the GMT3.5 model using reinforcement learning and got ChatGPT.
More details:
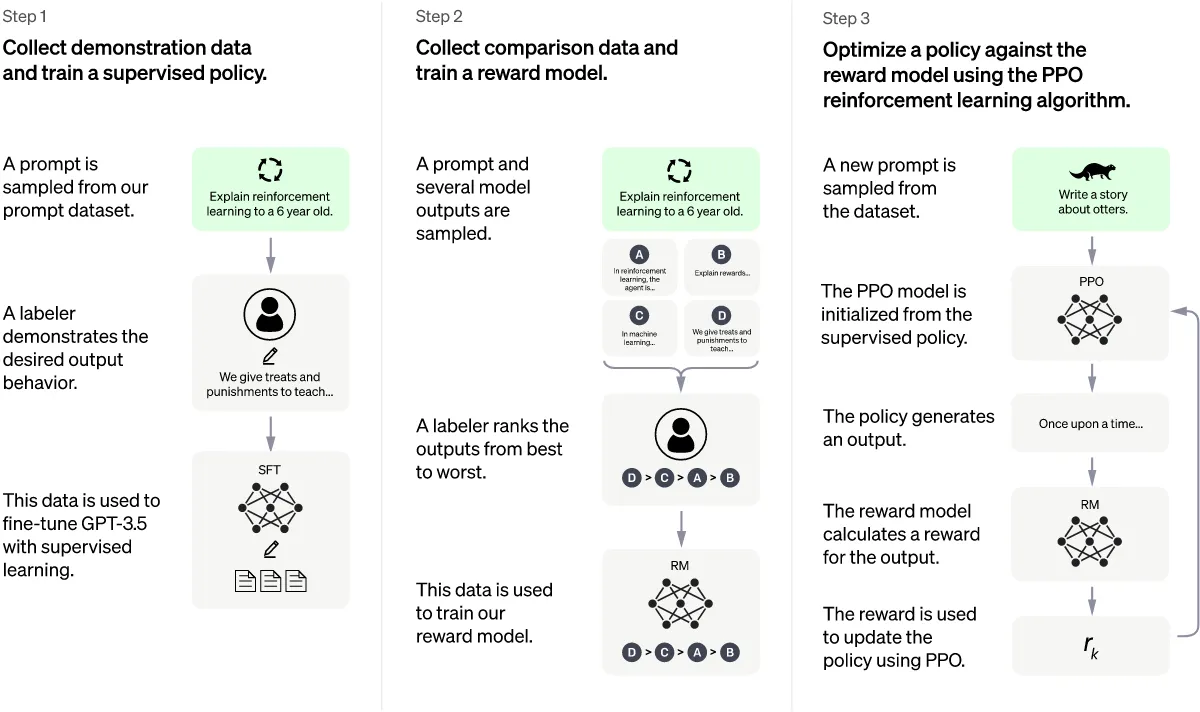
- Supervised Fine Tuning (SFT) Model (GMT 3.5 Model)
- Data collection: A certain request is selected from the database, the person gives the desired answer.
- This data is used to further train GPT 3 using supervised learning. Thus we got the SFT model (or GMT 3.5)
- Reward Model (needed to use reinforcement learning)
- Data collection: A certain request is selected from the database, GMT 3.5 generates several answers, a person sorts these answers from best to worst.
- This data is used to train the reward model. Input: request-response pair. Output: score (number).
- We use reinforcement learning
- The “policy” of the GMT 3.5 model is updated using the Proximal Policy Optimization (PPO) method:
- A request is selected from the database.
- The model generates a response.
- The Reward Model generates the score.
- We return to step 2 (a fixed number of times, then to step 1).
- During execution, the model's policy must change to maximize the score that is generated by the Reward Model.
SOURCES
Also read:
