- Introduction
- Apache Kafka
- Apache Kafka Data Structure
- Deploying a Kafka Cluster
- Testing the Fault Tolerance of an Apache Kafka Cluster
- Analyzing Apache Kafka Data Structure in Practice
- Conclusions
- Useful Links
Introduction
Message brokers act as intermediaries between message senders and receivers in distributed application systems. They provide methods for message transmission between applications and components, which is a key mechanism for asynchronous data exchange in modern information systems. This article explores Apache Kafka, a distributed messaging system that enables the transfer of data streams between different applications and services.
Distributed System
A distributed system is a collection of computer programs that use the computing resources of multiple individual nodes to achieve a common goal. It is also referred to as distributed computing or a distributed database. A distributed system is based on individual nodes that exchange data and synchronize across a shared network. Typically, nodes are separate physical hardware devices, but they can also be separate software processes or other recursively encapsulated systems. Distributed systems aim to eliminate bottlenecks or single points of failure in the system.
Distributed computing systems have the following characteristics.
- Resource Sharing: In a distributed system, resources such as hardware, software, or data can be shared among multiple components or applications.
- Parallel Processing: Multiple machines can simultaneously process the same function.
- Scalability: Computational power and performance can scale by adding additional machines as needed.
- Fault Detection: Fault detection is simplified in distributed systems.
- Transparency: Nodes can interact with and exchange data with other nodes in the system.
In a centralized computing system, all computations are performed on a single computer and in a single location. The main difference between centralized and distributed systems lies in the model of interaction among system nodes. In a centralized system, the state is stored in a central node that individual clients access individually. Since all nodes in a centralized system access the central node, it can lead to network congestion and slow down its operation. A centralized system has a single point of failure, whereas a distributed system does not have such a point.
Inter-Service Communication
There are two main types of communication between services: synchronous and asynchronous.
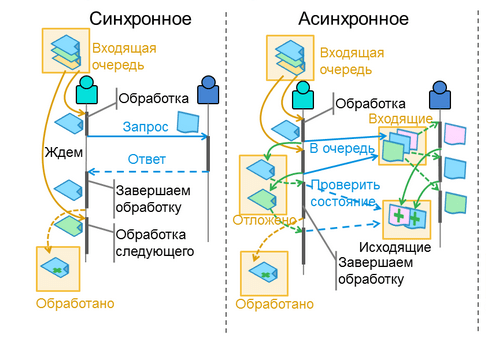
Synchronous communication between services means that one service has to wait for a response from another service before continuing its work. For example, if service A needs to retrieve data from service B, it has to send a request for the data and wait for a response from service B before continuing its work.
Asynchronous communication between services means that services interact with each other without waiting for a response. Instead, each service sends a request to perform a task and then continues its work without waiting for a response.
For more detailed information on methods of inter-service communication, you can refer to this article on Habr
Classic Message Queues
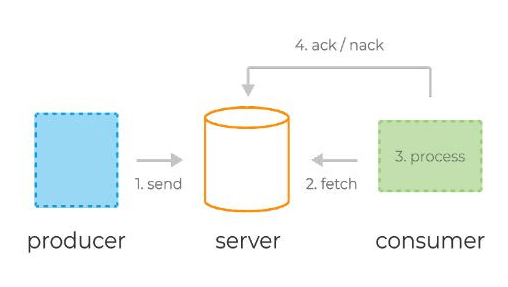
Message queue systems typically consist of three basic components:
- Server (broker): The server acts as a central component that manages the message queue and facilitates communication between producers and consumers.
- Producers: Producers are responsible for sending messages to a named queue that has been pre-configured by the administrator on the server.
- Consumers: Consumers read the messages from the queue as they appear. They retrieve the messages from the server (broker) using two different request models: pull or push.
Pull Model: In the pull model, consumers initiate the request to the server at regular intervals to fetch new messages. Each consumer sends a request to the server, asking for a new batch of messages. This approach allows consumers to control their own workload effectively. Additionally, the pull model enables batching of messages, which can improve throughput. However, one potential drawback of the pull model is the potential for imbalanced load distribution among different consumers and higher message processing latency.
Push Model (RabbitMQ): In the push model, the server actively pushes new messages to the consumers. The server makes a request to the client, sending them a new batch of data. This model reduces message processing latency and allows for efficient load balancing of messages among consumers.
Typical lifecycle of messages in message queue systems:
- Producers send messages to the server.
- Consumers fetch (or retrieve) messages along with a unique identifier from the server.
- The server marks the messages as "in-flight." These messages are still stored on the server but are temporarily not delivered to other consumers. The timeout of this state is controlled by a specific setting.
- Consumers process the messages according to business logic and then send an ack (acknowledgment) or nack (negative acknowledgment) request back to the server using the previously obtained unique identifier. This either confirms successful message processing or signals an error.
- If the processing is successful, the message is permanently removed from the server. In case of an error or timeout in the in-flight state, the message is redelivered to the consumer for reprocessing.
Apache Kafka
Apache Kafka is a platform used for building real-time data streaming pipelines and applications that adapt to data streams. It combines messaging, storage, and stream processing, allowing you to store and analyze both historical and real-time data.
Kafka provides three main functions to users:
- Publish and subscribe to streams of records
- Store streams of records efficiently in the order they were created
- Process streams of records in real-time
The key entities in Apache Kafka are:
- Broker: This is the core component responsible for storing and managing the data streams. It receives, stores, and distributes messages between producers and consumers.
- ZooKeeper: It is a separate auxiliary product used for storing cluster state, configuration, and metadata.
- Kafka Cluster: It is a group of Kafka brokers that work together to store and process messages. The cluster provides scalability, fault tolerance, and load balancing.
- Producer: It is a component that creates and sends messages to the Kafka broker. A producer can be associated with multiple topics and can send messages to multiple brokers.
- Topic: It is a category or channel to which a producer publishes messages and from which a consumer reads them. A topic represents a logical unit of message grouping. Messages are sent in the order they arrive (FIFO).
- Consumer: It is a component that reads and processes messages from the Kafka broker. A consumer can be associated with multiple topics and can receive messages from multiple brokers. Consumers read messages from partitions within a topic and maintain their offset to track read progress.
Like message queue services, Kafka consists of three components:
- Server (broker)
- Producers - they send messages to the broker
- Consumers - they read these messages using a pull model
Perhaps the fundamental difference between Kafka and message queues lies in how messages are stored on the broker and consumed by consumers.
- In Kafka, messages are not deleted by brokers as consumers process them - data in Kafka can be stored for days, weeks, or even years.
- Because of this, the same message can be processed multiple times by different consumers and in different contexts.
This is the main power and differentiator of Kafka compared to traditional message exchange systems.
Kafka follows a pull-based approach, allowing users to request batches of messages from specific offsets. Users can use batch processing of messages to increase throughput and efficient message delivery.
What is Apache Kafka used for?
Apache Kafka is best suited for streaming data from point A to point B without complex routing but with maximum throughput. It excels in stream processing and modeling changes in the system as a sequence of events. Kafka can also be used for data processing in multi-stage pipeline processing. Kafka is a great solution when you need a framework for storing, reading, re-reading, and analyzing streaming data. Its strength lies in real-time data processing and analysis. It is an ideal choice for persistent messaging or systems that require regular checkups.
Where can Apache Kafka be used?
- Logs and Metrics: Kafka can be used for collecting, storing, and analyzing logs and metrics to extract valuable information about the system.
- Microservices Architecture: Apache Kafka can be used for communication and synchronization between microservices in a distributed system. It can be used to transmit messages and events between different services, ensuring reliable delivery and message processing.
- Stream Processing: Apache Kafka can be used for real-time stream processing. It can ingest data streams from various sources such as sensors, IoT devices, etc., and process them almost instantaneously. This makes it ideal for tasks like machine learning, data analysis, and monitoring.
- Web Consumer Analytics: Apache Kafka can be used for analyzing web consumer behavior by processing real-time data from various sources. For example, it can be used to build a recommendation system that processes user behavior data and provides personalized recommendations.
- Data Integration and Stream Processing: Apache Kafka can be used for integrating and processing data in real time with other systems such as databases, data management systems, and other data sources. It provides powerful capabilities for performing streaming data transformations and aggregations.
- Persistence Logs: Kafka can be used as persistence logs for storing and recovering data. It can be used to record and restore the system's state in case of failures, etc.
Apache Kafka Data Structure
Messages in Kafka are organized and stored in named topics, where each topic consists of one or more partitions distributed across brokers within a cluster. This distribution is important for horizontal scaling of the cluster as it allows clients to write and read messages from multiple brokers simultaneously.
When a new message is added to a topic, it is actually written to one of the partitions of that topic. Messages with the same keys are always written to the same partition, ensuring order or sequencing of writes and reads.
To ensure data durability, each partition in Kafka can be replicated n times, where n is the replication factor. This guarantees the presence of multiple copies of the message stored on different brokers.
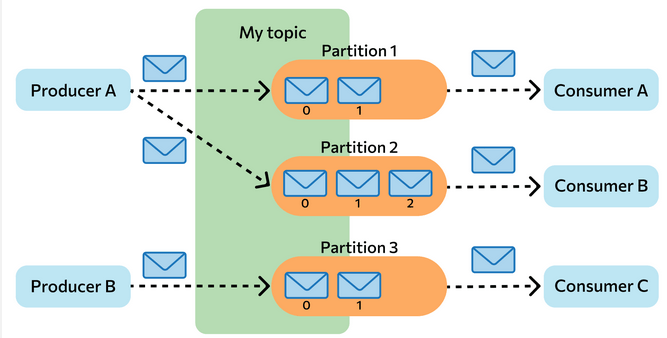
At each partition, there is a "leader" - a broker that handles client requests. The leader is responsible for interacting with producers and, in general, serving messages to consumers. Followers are other brokers that store replicas of all partition data. Followers send requests to the leader. Messages are always sent to the leader and, in general, read from the leader.
To determine which broker is the leader for a partition, clients request metadata from any broker in the cluster.
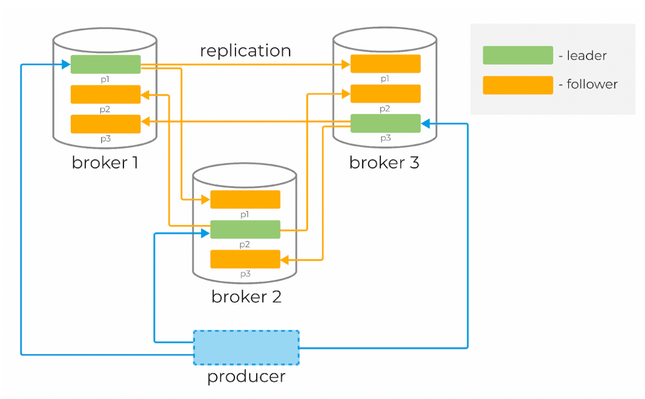
The main data structure in Kafka is a distributed, replicated log. Each partition is essentially a replicated log stored on disk. When a producer sends a new message to a partition, it is appended to the "head" of that log and assigned a unique, monotonically increasing offset (a 64-bit number assigned by the broker).
Kafka topic data typically consists of three types of files: .log files, .index files, and .timeindex files. Each file contains different data and information about the offsets of messages in the topic:
- .log files: They contain the actual messages sent to the topic. Each message is written to a separate line in the .log file. The .log files store the raw data and are used to persist Kafka messages on disk.
- .index files: They contain indexes for fast message lookup in the .log files. Each index points to the offset of a message in the .log file. Indexes facilitate efficient searching of messages by offset, making it faster and more efficient.
- .timeindex files: They contain time-based indexes for fast message lookup in the .log files. Each index points to the offset of a message in the .log file associated with a specific time. This allows for quick retrieval of all messages sent within a specific time range.
Together, these files enable Kafka to efficiently store and process messages in topics. By tracking offsets, it becomes easy to consume sequential messages and locate specific messages by time or offset.
As we have already established, messages are not deleted from the log after being consumed and can be read multiple times. The duration of data retention on the broker can be controlled through special settings. The message retention duration does not affect the overall system performance. Therefore, it is perfectly normal to store messages in Kafka for days, weeks, months, or even years.
Deploying a Kafka Cluster
- Package Installation and Directory Setup
- Create a folder for the cluster.
- Create working directories for three Kafka nodes: kafka_server_1, kafka_server_2, and kafka_server_3.
- Download, extract, and copy the contents into each of the broker directories. https://kafka.apache.org/downloads:
- Node Configuration
- Kafka Broker Configuration (from directories kafka_server_1, kafka_server_2, and kafka_server_3, respectively)
config/server.properties- Broker ID (0, 1, 2)
- Client port (9092, 9093, 9094)
- Zookeeper port (2181, 2182, 2183)
- Log directories (/tmp/kafka-logs-1, /tmp/kafka-logs-2, /tmp/kafka-logs-3)
broker.id=0
listeners=PLAINTEXT://:9092
zookeeper.connect=localhost:2181
log.dirs=/tmp/kafka-logs-1- Zookeeper Node Configuration:
config/server.properties- Data directory (/tmp/zookeeper_1, /tmp/zookeeper_2, /tmp/zookeeper_3)
- Client port (2181, 2182, 2183)
- Maximum number of client connections and connection limits
- Data exchange ports between nodes (i.e., informing each node about the existence of others)
dataDir=/tmp/zookeeper_1
clientPort=2181
maxClientCnxns=60
initLimit=10
syncLimit=5
tickTime=2000
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890 - Create directories for Zookeeper nodes and write node IDs to the respective service files:
mkdir -p /tmp/zookeeper_[1..3]
echo "1" >> /tmp/zookeeper_1/myid
echo "2" >> /tmp/zookeeper_2/myid
echo "3" >> /tmp/zookeeper_3/myid
- Start Zookeeper nodes and brokers
To start the cluster, run the following scripts from each root directory (kafka_server_1, kafka_server_2, and kafka_server_3):
sudo bin/zookeeper-server-start.sh config/zookeeper.pro - Create a topic, producer, and consumer:
sudo bin/kafka-topics.sh --create --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --replication-factor 3 --partitions 3 --topic TestTopic Created a topic with 3 partitions on 3 servers and replicated all partitions on each server (replication factor).
You can get information about the topic using the following command:
bin/kafka-topics.sh --describe --topic TestTopic --bootstrap-server localhost:9094
Result:

- Leader - the server with the primary replica of the partition
- Replica - the server where the information is duplicated
- ISR - in-sync replicas, servers that take over the leader role in case of leader failure
Testing the Fault Tolerance of the Apache Kafka Cluster:
- First, create console producers and consumers:
sudo bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic TestTopic
sudo bin/kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --from-beginning --topic TestTopic 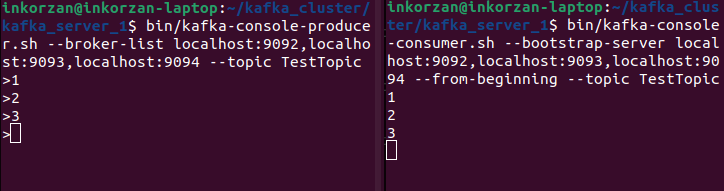
On the right side, a producer is running, sending messages, and on the left side, a consumer is running, reading messages.
- Let's stop one of the Kafka nodes (kafka_server_1):

We can see that the Leader and ISR parameters have changed. For Partition 1, the leader has changed from the first broker with id=0 to the second broker with id=1, which is expected according to the ISR parameter.
Let's try to write a message after stopping the first broker:
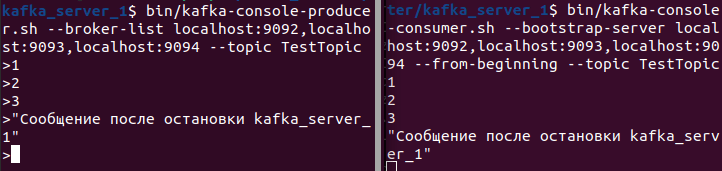
We can see that the message was successfully sent.
- Now let's stop one of the Kafka nodes (kafka_server_1):

Since only one broker is still running, it becomes the leader for all partitions.
Let's try to write a new message:
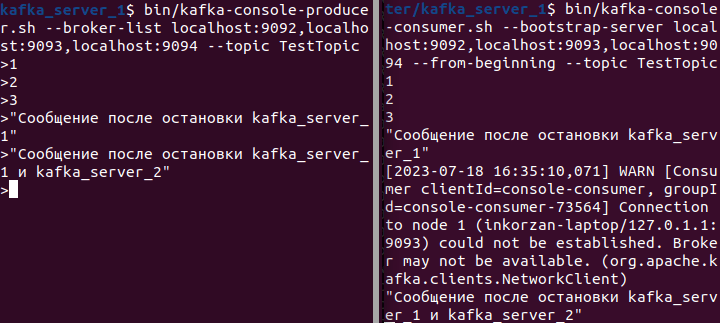
Once again, we can see that the message was successfully sent. Thus, we observe the fault tolerance of the Kafka cluster.
ANALYZING THE STRUCTURE OF APACHE KAFKA DATA IN PRACTICE
- Let's create a new topic with 3 partitions and 3 replicas on 3 brokers. To evenly distribute writes across all partitions from a single consumer, we need to add the RoundRobin class to the config/producer.properties file:
partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner ) 
Three directories have been created in the Kafka broker's log directories:
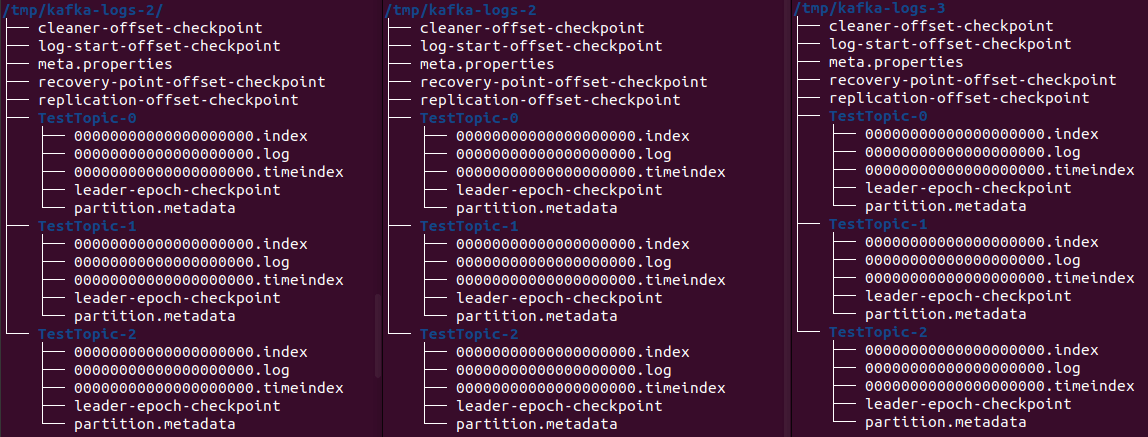
We have created three partitions in the topic, and each partition has its own directory in the file system on each broker. The leader-epoch-checkpoint stores information about the current leader's epoch number and its ID, as well as information about the last applied and sent log entries for each leader. This is used to control duplicate operations and reorder records in case of a failure or leader change. The partition.metadata contains information about each partition of the topic in the Kafka cluster. They include the following information:
- Partition ID: a unique identifier for the partition within the topic.
- Topic ID: the identifier of the topic to which the partition belongs.
- Leader: the broker that is the leader of the partition and is responsible for reading and writing data to that partition.
- Replicas: all brokers that contain a copy of the partition.
- Version: the current version of the partition metadata.
- State: the state of the partition, such as "Online" or "Offline".
The log-start-offset-checkpoint parameter is also visible, which is used in Apache Kafka to store information about the last written offset in the log for each partition. This is necessary for resuming data consumption from where the consumer left off and for recovery after a failure. If a Kafka broker fails, it can recover from the last saved checkpoint file. This allows the broker to restore data and its state to the point of failure.
- Let's add some messages to the topic. We will connect to the first broker as a producer, which is the leader of one of the partitions, and send a few messages to it:

The messages are written to the .log file, so we can see where the messages were written - to partition TestTopic-1:
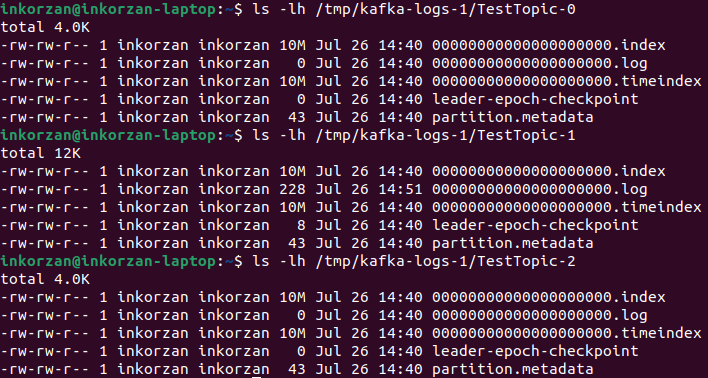
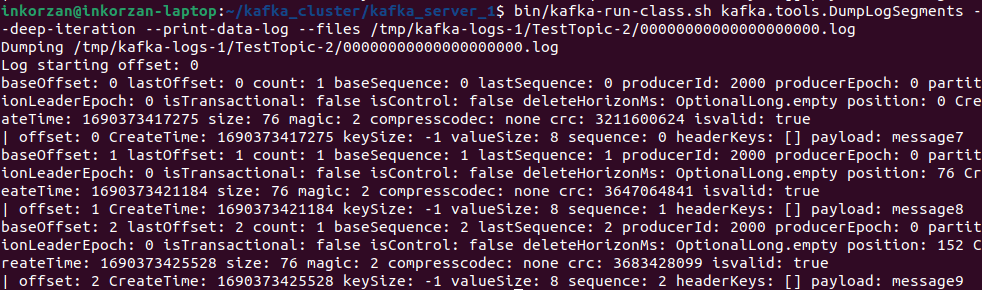
Each new message in a partition is assigned an ID that is one greater than the previous one. This ID is also called an offset. The first message has an offset of 0, the second has an offset of 1, and so on, with each subsequent message always being one greater than the previous one. Let's verify this using the kafka tool in our example:
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/kafka-logs-1/TestTopic-1/00000000000000000000.log 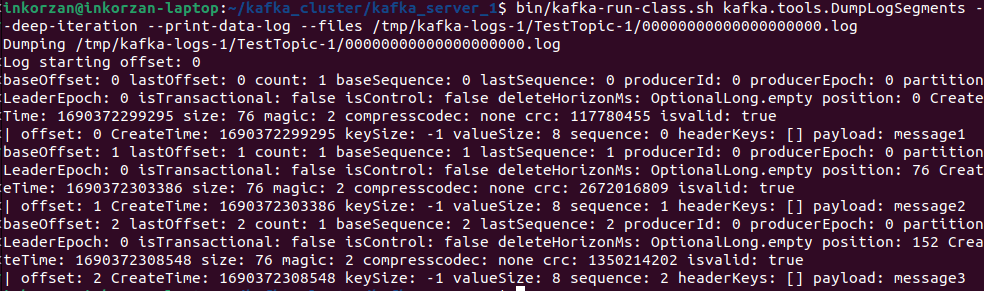
Here, we can see the offset, create time, key size, value size, and the message payload.
- Let's make sure that when connecting to different brokers, the write operation is performed only on the partition for which the broker is the leader. We'll connect to the second broker and write a few messages to it:

Let's check which partition the data was written to:
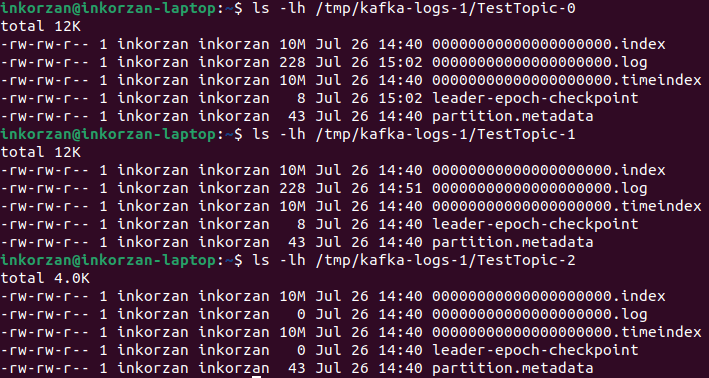
The size of the log file for TestTopic-0 has changed. Let's check if there are any messages in it that we sent to the second broker:
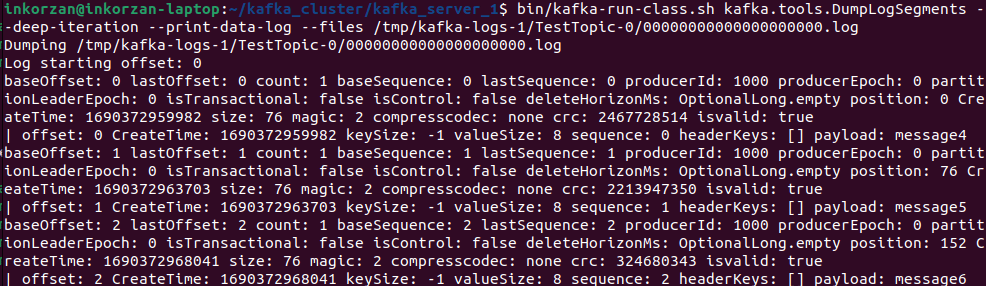
We can see that the sent messages were written to the TestTopic-0 partition.
Let's repeat the same steps for the third broker.

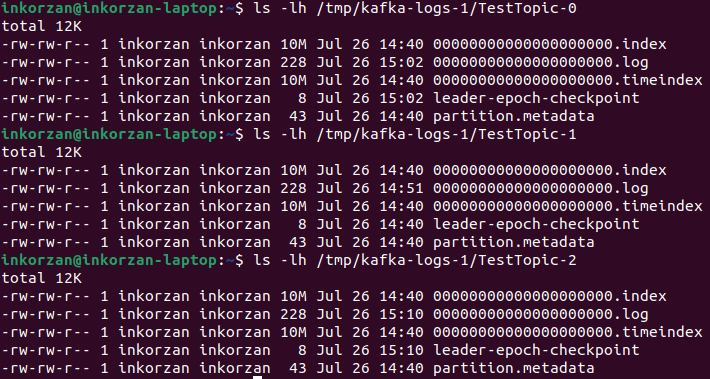
Based on the observations, we can conclude that the first broker is the leader for the TestTopic-1 partition, the second broker is the leader for the TestTopic-0 partition, and the third broker is the leader for the TestTopic-2 partition.
CONCLUSIONS
The main advantages of Apache Kafka lie in its scalability, fault-tolerance, and high-speed data processing capabilities. It is capable of handling and delivering millions of messages per second, making it an ideal choice for use in high-throughput systems. Apache Kafka also has a flexible architecture and supports multi-language APIs, allowing developers to integrate it with various applications and platforms. It also supports both horizontal and vertical scaling, making it easy to expand and adapt the system according to changing needs. Overall, Apache Kafka is a powerful and efficient system for real-time data stream processing. It provides developers with extensive capabilities and enables them to effectively manage and process large volumes of data.
USEFUL LINKS
- Official Apache Kafka website
- Apache Kafka installation files
- Apache Kafka: Basics of the Technology
- Understanding Message Brokers
- Example of Deploying an Apache Kafka Cluster
- Installing an Apache Kafka Cluster
- A Practical Look at Data Storage in Apache Kafka
- Service Interaction
Also read:
